When will I get to 1,000,000 Anki reviews?
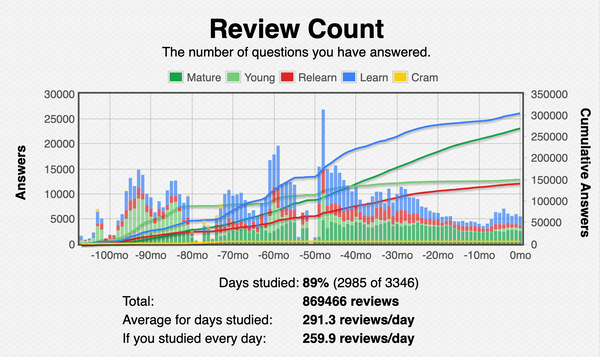
Recently I’ve been wondering how long it would take me to get to 1,000,000 reviews. Right now I’m sitting at between 800,000 and 900,000 reviews and for no other reason than pure ridiculous curiosity I was curious whether I could get SQLite to compute it directly for me. Turns out the answer is “yes, you can.”
Here’s the query in its gory detail and then I’ll walk through how it works:
Fix your Anki streak - the script edition
AwesomeTTS Anki add-on: Use Amazon Polly
As its name implies, the AwesomeTTS Anki add-on is awesome. It’s nearly indispensable for language learners.
You can use it in one of two ways:
- Subscribe on your own to the text-to-speech services that you plan to use and add those credentials to AwesomeTTS. (à la carte)
- Subscribe to the AwesomeTTS+ service and gain access to these services. (prix fixe)
Because I had already subscribed to Google and Azure TTS before AwesomeTTS+ came on the scene, there was no reason for me to pay for the comprehensive prix fixe option. Furthermore, since I’ve never gone above the free tier on any of these services, it makes no sense for me to pay for something I’m already getting for free. For others, the convience of a one-stop-shopping experience probably makes the AwesomeTTS+ service worthwhile.
Anki: Insert the most recent image
I make a lot of Anki cards, so I’m on a constant quest to make the process more efficient. Like a lot of language-learners, I use images on my cards where possible in order to make the word or sentence more memorable.
Process
When I find an image online that I want to use on the card, I download it to ~/Documents/ankibound. A Hazel rule then grabs the image file and converts it to a .webp file with relatively low quality and a maximum horizontal dimension of 200px. The size and low quality allow me to store lots of images without overwhelming storage capacity, or more importantly, resulting in long synchronization times.
Altering Anki's revlog table, or how to recover your streak
Anki users are protective of their streak - the number of consecutive days they’ve done their reviews. Right now, for example, my streak is 621 days. So if you miss a day for whatever reason, not only do you have to deal with double the number of reviews, but you also deal with the emotional toll of having lost your streak.
You can lose your streak for one of several reasons. You could have simply been lazy. You may have forgotten that you didn’t do your Anki. Or travel across timezones put you in a situation where Anki’s clock and your clock differ. Others have described a procedure for resetting the computer’s clock as a way of recovering a lost streak. It apparently works though I haven’t tried it. Instead I’ll focus on a technique that involves working directly with the Anki database.
A deep dive into my Anki language learning: Part III (Sentences)
Welcome to Part III of a deep dive into my Anki language learning decks. In Part I I covered the principles that guide how I setup my decks and the overall deck structure. In the lengthy Part II I delved into my vocabulary deck. In this installment, Part III, we’ll cover my sentence decks.
Principles
First, sentences (and still larger units of language) should eventually take precedence in language study. What help is it to know the word for “tomato” in your L2, if you don’t know how to slice a tomato, how to eat a tomato, how to grow a tomato plant? Focus on larger units of language increases your success rate in integrating vocabulary into daily use.
A deep dive into my Anki language learning: Part II (Vocabulary)
In Part I of my series on my Anki language-learning setup, I described the philosophy that informs my Anki setup and touched on the deck overview. Now I’ll tackle the largest and most complex deck(s), my vocabulary decks.
First some FAQ’s about my vocabulary deck:
- Do you organize it as L1 → L2 or as L2 → L1, or both? Actually, it’s both and more. Keep reading.
- Do you have separate subdecks by language level, or source, or some other characteristic? No, it’s just a single deck. First, I’m perpetually confused by how subdecks work. I’d rather subdecks just act as organizational, not functional, tools. But other users don’t see it that way. That’s why I use tags rather than subdecks to organize content.1
- Do you use frequency lists? No, I extract words from content that I’m reading, that I encounter when listening to moviews or podcasts, or words that my tutor mentions in conversation. That’s what goes in Anki.
Since this is a big topic, I’m going to start with a quick overview of the fields in the main note type that populates my vocabulary deck and then go into each one in more detail and how they fit together in each of my many card types. At the very end of the post, I’ll talk about verb cards which are similar in most ways to the straight vocabulary card, but which account from the complexities of the Russian verbal system.2
A deep dive into my Anki language learning: Part I (Overview and philosophy)
Although I’ve been writing about Anki for years, it’s been in bits and pieces. Solving little problems. Creating efficiencies. But I realized that I’ve never taken a top-down approach to my Anki language learning system. So consider the post the launch of that overdue effort.
Caveats
A few caveats at the outset:
- I’m not a professional language tutor or pedagogue of any sort really. Much of what I’ve developed, I’ve done through trial-and-error, some intuition, and a some reading on relevant topics.
- People learn differently and have different goals. This series will be exclusively focused on language-learning. There are similarities between this type of learning and the memorization of bare facts. But there are important differences, too.
- As I get further and further into the details, more and more of what I discuss will be macOS specific. I’m not particularly opinionated about operating systems. And my preference has more to do with the accumulated weight of what I’m accustomed to and as a consequence, the potential pain of switching. In the sections that deal with macOS specific solutions, feel free to skip over that content or read it with a view toward thinking about parallel tools on whatever OS you are using.
- I use Anki almost exclusively for Russian language acquisition and practice. Of necessity, some particularities of the language are going to dictate the specific issues that you need to solve for. For example, if verbs of motion aren’t part of the grammar of your target language (TL) then rather than getting lost in those weeds, think about what unique counterparts your TL does have and how you might adopt the approaches I’m presenting.
We that out of the way, let’s dive in!
A tool for scraping definitions of Russian words from Wikitionary
WiktionaryParser module which is good but misses some important edge cases. So I rolled up my sleeves and crafted my own solution. As with WiktionaryParser the heavy-lifting is done by the Beautiful Soup parser. Much of the logic of this tool is around detecting the edge cases that I mentioned. For example, the underlying HTML format changes when we’re dealing with a word that has multiple etymologies versus those with a single etymology. Whenever you’re doing web scraping you have to account for those sorts of variations.
Getting plaintext into Anki fields on macOS: An update
A few years ago, I wrote about my problems with HTML in Anki fields. If you check out that previous post you’ll get the backstory about my objection.
The gist is this: If you copy something from the web, Anki tries to maintain the formatting. Basically it just pastes the HTML off the clipboard. Supposedly, Anki offers to strip the formatting with Shift-paste, but I’ve point out to the developer specific examples where this fails. Basically, I only want plain text. Ever. I will take care of any and all formatting needs via the card templates. Period.