Encoding of the Cyrillic letter й - a UTF-8 gotcha
In the process of writing and maintaining a service that checks Russian word frequencies, I noticed peculiar phenomenon: certain words could not be located in a sqlite database that I knew actually contained them. For example, a query for the word - английский consistently failed, whereas other words would succeed. Eventually the commonality between the failures became obvious. All of the failures contained the letter й , which led me down a rabbit hole of character encoding and this specific case where it can go astray.
Background on Unicode support for Cyrillic characters
Cyrillic characters are found in the 00000400 range of the Unicode table.
The letter Russian й is related to its cousin и but is regarded as a separate letter. In other words, it’s not an и plus a combining diacritical mark; it has its own entry in the Unicode table:

A brief digression on Unicode vs UTF-8
True confession: I’ve harboured some confusion between the concepts of Unicode and UTF-8. Solving this problem meant diving into this a little deeper. First, a really basic distinction:
- Unicode is a character set that aims to encompass all possible characters.
- UTF-8 is a flexible way of encoding Unicode characters in strings
Looking at the й
entry above, we see that the Unicode value is U+0439 which is the hexadecimal value 0h0439 and it has a UTF-8 encoding of D0 B9. How do we get D0 B9 from U+0439? Herein lies the distinction between Unicode and UTF-8. In the old days, when computers just had to deal with the Latin alphabet, ASCII was sufficient. It was capable of encoding 127 characters which was more than enough to store English language text. But how to deal with characters in other languages? Clearly 8 bits is not going to be enough. So we’ll solve it by giving it an entry in the Unicode table. Problem solved. Not quite. We could just store all text as multi-byte sequences. For sure it’s necessary for some Asian languages, notably Chinese. But if would be inefficient for English, where most of what we write and store is rendered in the Latin alphabet (which resides in the lowest 127 entries in the Unicode table.)
One of the answers to this dilemma is UTF-8 which flexibly encodes characters of varying Unicode width. I’ll simply a bit here. For characters with Unicode values of 0-127, we can just store the character as a single byte. Nice and compact. For Unicode characters with larger values then we have to distribute their values into bytes that have fixed identifying “header bits” (my terminolgy, don’t quote me.) For Unicode values up to 0h07FF we take 11 bits of the Unicode value and insert it into two bytes with a fixed format:
| Byte 1 | Byte 2 | Byte 3 | Byte 4 | # free bits | Maximum Unicode value |
|---|---|---|---|---|---|
0xxxxxxx |
- | - | - | 7 | 0h7F |
110xxxxx |
10xxxxxx |
5+6 → 11 | 0h7FF | ||
1110xxxx |
10xxxxxx |
10xxxxxx |
4+6+6 → 16 | 0hFFFF | |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
3+6+6+6 → 21 | 0h10FFFF |
From here, you’ll have to trust me. If you distribute the bits of U+0439 into the 11 free bits of the 2 byte UTF-8 sequence, you end up with D0 B9.
Now to why this matters for my problem of finding й -containing words.
A discovery
After it dawned on me that some errant encoding might be the cause of the problem. I decided to do a little print debugging and capture what my API was seeing for characters
for l in word:
print(l.encode('utf-8'))So for the word численный for example, what were we seeing?
b'\xd1\x87'
b'\xd0\xb8'
b'\xd1\x81'
b'\xd0\xbb'
b'\xd0\xb5'
b'\xd0\xbd'
b'\xd0\xbd'
b'\xd1\x8b'
b'\xd0\xb8'
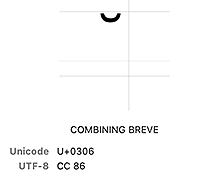
b'\xcc\x86'Whoa, were is the D0 B9 (U+0439) that we would expect? The problem is right in front of us now. The last two characters in the UTF-8 string are \xd0\xb8 and \xcc\x86. What are those guys? Well, it turns out that the letter и
has a Unicode value of U+0438 and a UTF-8 encoding, therefore of D0 B8. Then what follows it is probably a diacritical mark. Which one? Knowing now how UTF-8 is constructed, we can work backwards. CC86 is 11001100 10000110 in binary format. If we extract out the fixed bits of the two-byte sequence, we’re left with 01100000110 which is 0h306. Looking up U+0306 in the Unicode table, we find:
{kind=link}
{kind=link}
Therein lies the problem. Somewhere the й got turned into и plus a combining breve diacritical mark.
The solution
Since I’m not able to control the process that led to this bungling of the encoding, all I can do is fix it on the back end. Therefore, we just do a character substitution:
word = word.replace(u"\u0438\u0306", u"\u0439")Any time we have this stupid encoding, we just fix it before using the word. Now I’m willing to bet that ё is going to get handled the same way.
Problem solved!