I’ve recently discovered the L-R system of language learning and have been setting up to learn it.
The idea is that you begin with long texts - novels, for example - in your target language (L2) and follow a systematic approach to reading and listening.
L-R system in a nutshell
Here are the steps:
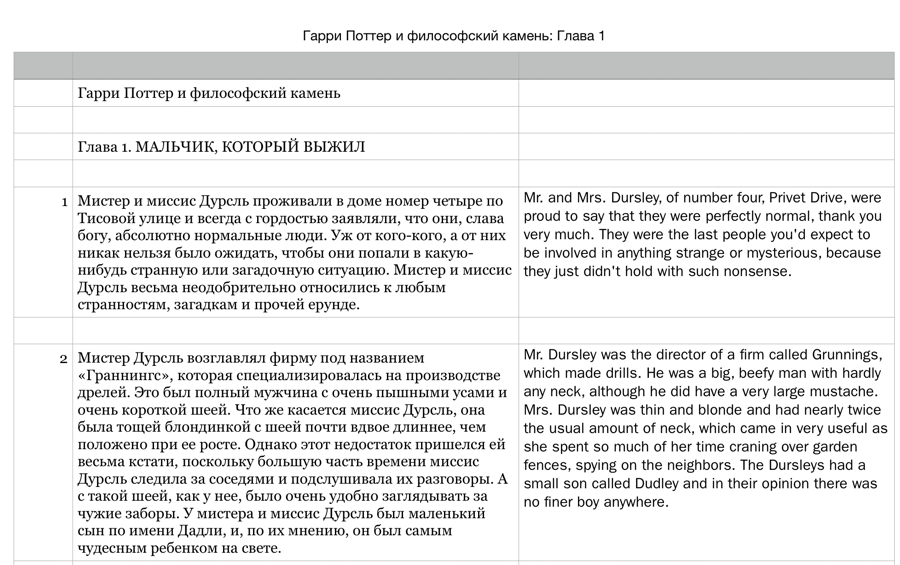
- Read the text in L1 (your native language) and become familiar with it.^[I rephrased this intruction from other sources that say “read the translation” because what if the text itself if a translation? For example, my first text to try this with is Гарри Поттер и философский камень
which was originally written in English and then translated into Russian, among other languages. So, it’s best to say for the first step “Read the text in your L1 and become very very familiar with what it says.”]
- Listen to the recording and simultaneously read the text in L2.
- Listen to the recording while reading the text in L1.
- Repeat after the speaker. But only do this once you truly understand the meaning of what you’re repeating. The goal is meaning, not only pronunciation.
- Translate the text from L1 to L2 by covereing up one side while reading the other.
Tips
It is hard, very hard in fact, to find parallel texts. Even if you can find .txt documents online, the formatting is a challenge. Columns in Word or Pages simply don’t work, because the L2 and L1 doesn’t line up properly. So here’s what I did for formatting Harry Potter and the Philosopher’s Stone^[Before you accuse me of intellectual property theft, I will mention that I own both the Russian translation and the English language original in book form. So no harm done to anyone.]: