Serious audio processing on the command line
I’ve written previously about extracting and processing mp3 files from web pages. The use case that I described, obtaining Russian word pronunciations for Anki cards is basically the same although I’m now obtaining many of my words from Forvo. However, Forvo doesn’t seem to apply any audio dynamic range processing or normalization to the audio files. While many of the pronunciation mp3’s are excellent as-is, some need post-processing chiefly because the amplitude is too low. However, being lazy by nature, I set out to find a way of improving the audio quality automatically before I insert the mp3 file into my new vocabulary cards.
As before, the workflow depends heavily on Hazel to identify and process files coming out of Forvo. The download button on their website, sends the mp3 files to the Downloads directory. The first rule in the workflow just grabs downloaded mp3 files and moves them to ~/Documents/mp3 so that I can work on them directly there.
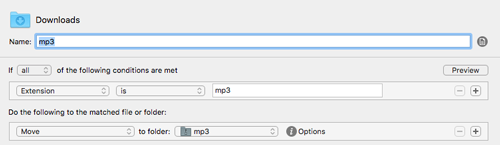
Another Hazel rule renames the verbosely-titled files to just the single Russian word being pronounced. It’s just neater that way.
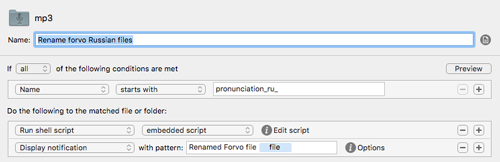
rename 's/(pronunciation_ru_)(.*)/$2/' *.mp3This uses the convenient rename command that you can obtain via Homebrew.
The final rule, grabs the newly-renamed mp3 file and performs a series of audio processing steps:
ffmpeg -i "$1" tmp.wav;
sox tmp.wav temp_out.wav norm gain compand 0.02,0.20 5:-60,-40,-10 -5 -90 0.1;
ffmpeg -i temp_out.wav -codec:a libmp3lame -qscale:a 2 tmp.mp3;
lame --mp3input -b 64 --resample 22.50 tmp.mp3 tmp;
mv tmp "$1";
rm tmp.mp3;
rm tmp.wav;
rm temp_out.wavThe first line ffmpeg -i "$1" tmp.wav; simply writes a temporary .wav file that we can process using sox. The second line invokes sox with a number of options that normalize and improve the dynamic range of the audio. Finally we use ffmpeg to convert the .wav file back to .mp3, compress the .mp3 file and then clean up.
Now I have excellent normalized audio for my cards, with no work for me!
See also:
- sox compand options - outlines a number of options for dynamic range compression using sox.
- Using ffmpeg to convert .wav to .mp3
- Using ffmpeg to convert .mp3 to .wav
- Introduction to processing audio files with SoX
- SoX homepage - the source